Containerization Fundamentals

Imagine: You are joining a team developing an application as a [test automation engineer|business analyst|developer]. There is a Dev, Stage and Production environment for the application (and the several other applications it integrates with). Dev is very unstable, constantly down and bloated with testing data. Something breaks and an investigation is required to determine if it was bad data, a new code change, or some external dependency. Or worse, nothing happens at all, and Dev just stays broken until the next deployment. Team members have come and gone and no one quite knows if Dev, Stage and Prod reflect the same environment conditions; they have drifted over time.
You have been handed a fresh set of requirements and asked to write an automated testing suite against the application in parallel to developers adding new features. Week one (and probably week two) is all about getting your environment set up, figuring out how the team functions, and how the application works. So where to even start? You might start by deciding this isn’t for you and update your LinkedIn profile as a “go-getter looking for a new opportunity.”

But: it doesn’t have to be this way! The real question is, “How?“
This is the first post in a series on containerization and how it can be leveraged to enable continuous integration and deployment, develop test automation, and improve the challenge of on-boarding new folks to the team. This series of posts have been adapted from a workshop created for the Quality Assurance Retreat. The goal is to be able to consume application containers (and new releases as they become available) and write tests against them in your own isolated, local environment.
But before we dive into the implementation, we need to take step back (and probably a deep breath after all that imagining). If you are like me, joining a new team or project always feels like a firehose of buzzwords and acronyms. The goal of this post is address those buzzwords, the underlying technology to containers, and a build a knowledge base that will ultimately help us use containers more effectively.
[Exhale here..]
Technology is full of buzzwords about the newest, shiniest thing you should definitely be using. And if you are not using <enter buzzword here> you are falling behind. I am not arguing that technology doesn’t move at a rapid pace, but I do think it’s important to slow down every once in a while and understand how something works, where it came from, what problems it solved, what problems it doesn’t solve. This becomes even more important when the next abstraction of an underlying technology is released, and then the next abstraction, and so on. With that mindset, I want to address the following questions:
- What is containerization?
- How is it different than virtualization?
- How does it work?
- Why should I care?
Containerization vs. Virtualization
Both allow applications to be isolated and portable by..
- bundling an application with all of its required configuration files, libraries and dependencies
- providing an application runtime environment that is independent (mostly) of the host environment
The difference is where the abstraction is implemented: at the hardware level (virtual machines) or application level (containers).
Virtual Machines
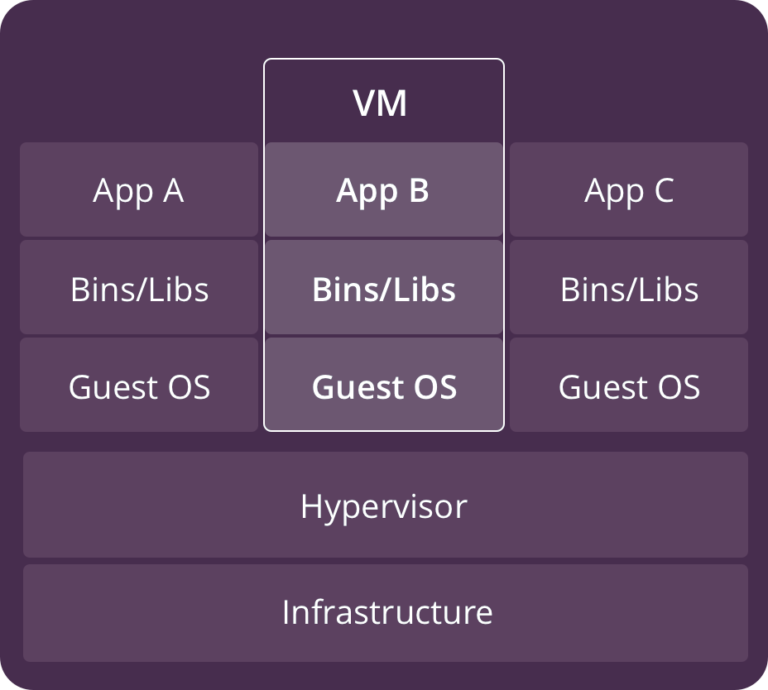
Virtual machines (VM) are an abstraction of the hardware layer. Each VM has its own copy of an operating system, applications, required files, libraries and dependencies. A hypervisor divides the physical hardware resources into smaller sets of virtual resources that can be used by the operating system inside each VM. This provides complete isolation of an OS and each utilizes its own kernel.
While VMs have the advantages of complete isolation, they introduce some new challenges. They are resource intensive (each has its own OS and partitioned resources). It is challenging to efficiently maximize the use of VM resources, especially in an environment where multiple applications need to be deployed. When multiple environments with different configurations are required (dev, stage, prod) VMs are difficult to manage and configuration drift happens easily. Virtual machine images are also not easily distributed as they are generally large in size.
Containers

Containers are an abstraction of the application layer. Containers run isolated processes but share a common operating system. System calls in containers are run on the same kernel running in the host OS. Containers also have copies of all the required files, libraries and dependencies. Unlike with VMs, no virtualization of resources (CPU/memory) is required. Each container does not need a copy of an operating system and therefore they are lightweight, easily stored and distributed. However, since containers do share the host kernel, they introduce a security risk of a compromised kernel impacting all containers running on that host.
How does containerization work?
Whereas virtualization requires a hypervisor to divide the physical hardware resources, containerization requires a container engine to provide process isolation and manage building and unpacking container images. Through a container engine, a process running in a container runs inside the host’s operating system but the process is isolated from other processes and can only see itself (and its packaged filesystem). These capabilities are possible through a few features: Linux Namespaces, Linux Control Groups (cgroups) and Open Container Initiative (OCI) runtime filesystems.
Linux Namespaces
Linux namespaces ensure that each process sees its own personal view of the systems. Namespaces exist for mount (files), process ID, network, inter-process communication, UTS and user ID. Each container uses its own namespace of each kind. For example, a container has its own network namespace, and each sees its own set of network interfaces. This container-specific network namespace provides network isolation.
Control Groups (cgroups)
Control groups organize processes in hierarchical groups and limit the amount of resources the process can consume – CPU, memory, network bandwidth, etc. Control groups ensure a process can’t use more than the configured amount of CPU, memory and network bandwidth. This mechanism simulates a process running on a separate machine as one process will not affect another.
OCI Runtime Filesystems
Container engines are also responsible for building application bundles (and unpacking at runtime) according the Open Container Initiative.This allows OCI images to be lightweight, distributable packages that can be easily downloaded and unpacked into a runtime filesystem bundle.
By combining Linux namespaces, control groups and a OCI runtime filesystem, we can establish a working definition for a container:
a process, with access to its packaged, runtime filesystem, running on the host OS that is isolated by namespaces and is resource constrained by control groups.
Why should I care?
I think we have all experienced this problem to some degree: Different software components running on the same machine will require different and possibly conflicting versions of dependent libraries or have different environment requirements in general. Containerization addresses the “runs on my machine” problems while also decoupling applications from deployment environments. I have outlined some of the benefits below:
- portability: containers can be host environment independent and configuration driven
- agility: images and containers enable DevOps tools and processes
- lightweight: a container is nothing more than a single isolated process running in the host OS that consumes only the resources the app consumes
- isolation: enabled by Linux namespaces
- efficient use of resources: enabled by Linux control groups
Containerization should radically change the way we think about how software is developed, released and deployed. Release and deploy are overloaded terms but in this case I am referring to release as creating an artifact that is able to be deployed. Following the standard of 12 factor applications, this means applications are developed and built into an executable bundle known as a build. When that build artifact (an image) is combined with configuration for a specific environment, that is a deployment (see figure).
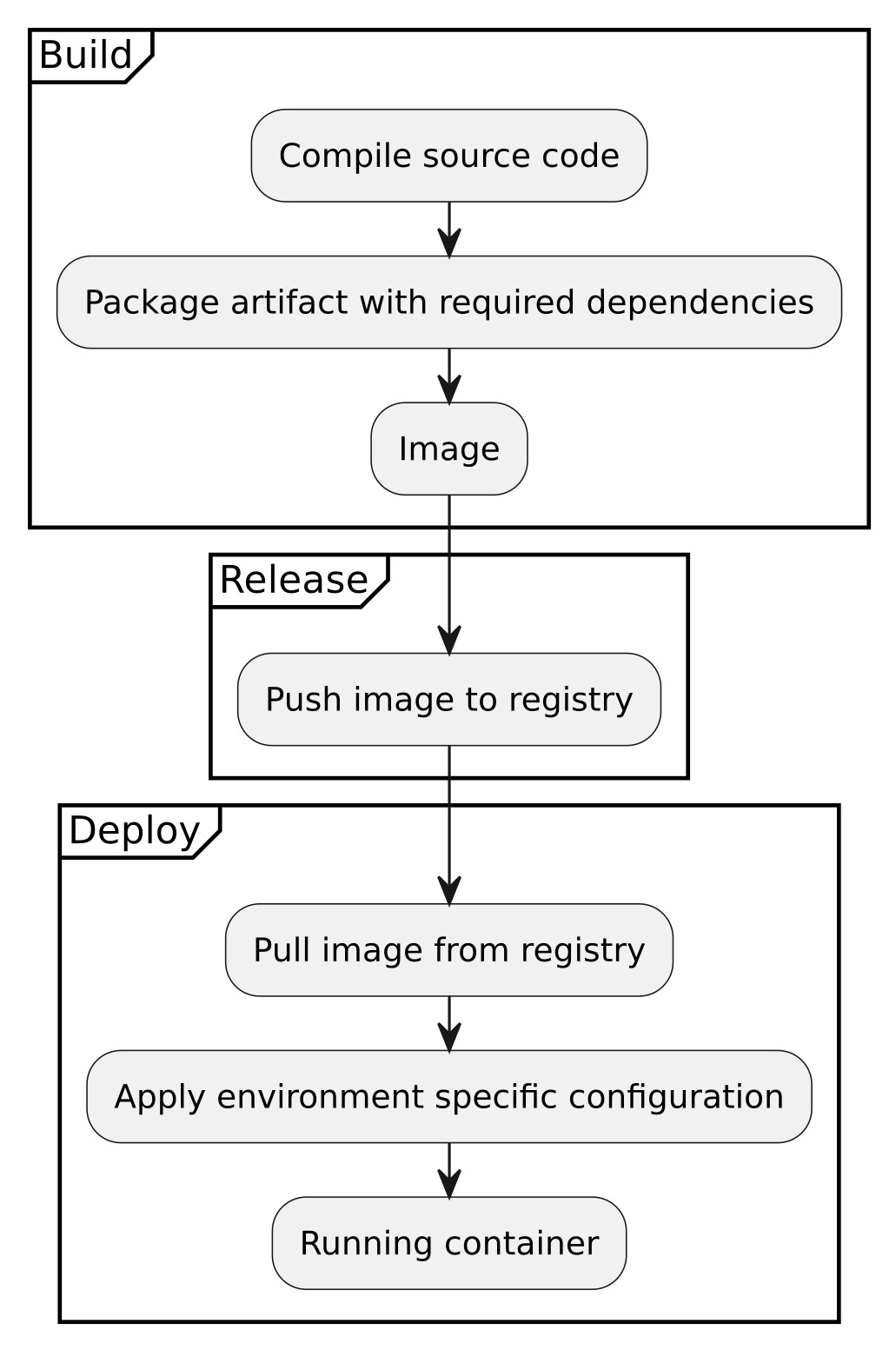
And in this workflow, deployment can be to production, to a local machine, a test environment. The point is that it doesn’t matter as long as the target environment has a container engine.
What’s Next?
Up to this point, I have not mentioned any tools that implement these capabilities. This was by design. The details outlined above are tool-independent. They are the transferable concepts across implementations whether it be Docker or any other containerization platform. The next steps are learning how these concepts are implemented by a specific tool. For example, how does Docker manage the packing and unpacking of the runtime filesystem? (Answer: Image layering – and it makes a lot more sense with these concepts in mind).
Containerization tools allow for the next level of abstraction which is container orchestration. These concepts are foundational to understanding orchestration and using tools such as docker swarm or kubernetes or <insert the latest container orchestration technology here>.
With this knowledge in hand, the next post will introduce Docker, a containerization platform for packaging, distributing and running containers and how we can use it to deploy an example application on our own machine. And in the final post, after successfully deploying our application locally, we will leverage some principles of containers to develop an API test against our application using the JavaScript bindings of Cucumber.
Posts in this containerization mini-series:
- Containerization Fundamentals
- Local Deployment using Docker
- Developing API tests with Cucumber and Docker